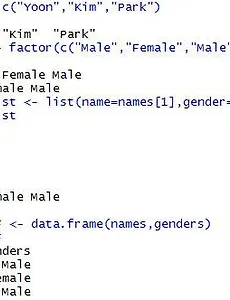
 [R 기초] 개요, 기초 데이터 구조
빅데이터의 개념 시스템, 서비스, 조직 등에서 주어진 비용, 시간 내에 처리 가능한 범위를 넘어서는 데이터즉, 기존 회사에서 시간이 부족해서, 기술이 받쳐주지 않아서 손댈 엄두를 못내던 데이터를 빅데이터라 하며엑셀이 없던 시절에는 엑셀로 처리 가능한 데이터도 빅데이터 였다.폭발적으로 증가하는 데이터 양 자체만 빅데이터로 치부하기엔 아쉬움이 있다. 형태가 어떻든 그것을 핸들링 할 수 있고, 가치를 찾아 낼 수 있으며, 처리 비용 대비 수익을 낼 수 있어야 유의미한 데이터라고 할 수 있다. 빅데이터의 네가지 특징 Value Volume - Terabytes, Records, TransactionVelocity - Batch, Near time, Real time, StreamsVariety - Structu..
2016. 2. 9.
[R 기초] 개요, 기초 데이터 구조
빅데이터의 개념 시스템, 서비스, 조직 등에서 주어진 비용, 시간 내에 처리 가능한 범위를 넘어서는 데이터즉, 기존 회사에서 시간이 부족해서, 기술이 받쳐주지 않아서 손댈 엄두를 못내던 데이터를 빅데이터라 하며엑셀이 없던 시절에는 엑셀로 처리 가능한 데이터도 빅데이터 였다.폭발적으로 증가하는 데이터 양 자체만 빅데이터로 치부하기엔 아쉬움이 있다. 형태가 어떻든 그것을 핸들링 할 수 있고, 가치를 찾아 낼 수 있으며, 처리 비용 대비 수익을 낼 수 있어야 유의미한 데이터라고 할 수 있다. 빅데이터의 네가지 특징 Value Volume - Terabytes, Records, TransactionVelocity - Batch, Near time, Real time, StreamsVariety - Structu..
2016. 2. 9.






