 데이터의 질 - intra-/inter-class variability
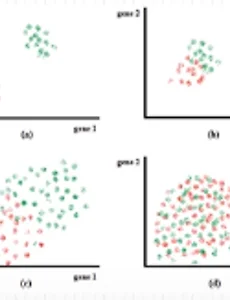
데이터의 질 - intra-/inter-class variability 데이터의 질에 따라 머신러닝을 통한 분석의 결과가 바뀐다 Intra- 클래스 내부의 분산이 어떤가Inter- 클래스간 분산이 어떠냐 위 이미지에서 위쪽 줄은 Intra-class variability가 작다 아래 줄은 크다왼쪽 두 산점도는 Inter-class variability가 크다 오른쪽 두 산점도는 작다 그래서 inter-가 크고 intra-가 작은 Input으로 만들어주는 것이 좋다= 클래스 별로 잘 구분되는 것이 좋고 클래스 내부에 서로 뭉쳐있는 것이 좋다 예) 성적을 예측하라X: 키, 몸무게, 사교육, IQ, 소득, 형제, 이성친구, 인터넷 사용시간, 게임 시간, 소비금액, 등등 high dimension - 다 때려 ..
2017. 7. 20.
데이터의 질 - intra-/inter-class variability
데이터의 질 - intra-/inter-class variability 데이터의 질에 따라 머신러닝을 통한 분석의 결과가 바뀐다 Intra- 클래스 내부의 분산이 어떤가Inter- 클래스간 분산이 어떠냐 위 이미지에서 위쪽 줄은 Intra-class variability가 작다 아래 줄은 크다왼쪽 두 산점도는 Inter-class variability가 크다 오른쪽 두 산점도는 작다 그래서 inter-가 크고 intra-가 작은 Input으로 만들어주는 것이 좋다= 클래스 별로 잘 구분되는 것이 좋고 클래스 내부에 서로 뭉쳐있는 것이 좋다 예) 성적을 예측하라X: 키, 몸무게, 사교육, IQ, 소득, 형제, 이성친구, 인터넷 사용시간, 게임 시간, 소비금액, 등등 high dimension - 다 때려 ..
2017. 7. 20.




