cafe.daum.net/moonikan
김문주
moonikan@gmail.com
빅데이터 : 시스템, 서비스, 조직 등에서 주어진 비용, 시간 내에 처리 가능한 범위를 넘어서는 데이터
빅데이터 4V : Volume(10 TB 이상),
Velocity(Batch, Near time, Real time, Streams),
Variety(Structured, Unstructured, Semi-structured)
Value
Hadoop 아파치 프로젝트 중 DB쪽에 위치하며, 인프라쪽으로 가고 있다
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models
Spark 아파치 프로젝트 중 실시간 분석
Apache Spark™ is a fast and general engine for large-scale data processing.
Hadoop에 비해 빠른 속도 (RAM을 활용하며, RDD(Resilient Distributed Datasets)특성, DAG(Direct Acydic Graph)디자인, Lineage(Transformations, Actions), Narrow dependency)
Speed
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
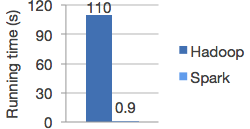
Logistic regression in Hadoop and Spark
Ease of Use
Write applications quickly in Java, Scala, Python, R.
Generality
Combine SQL, streaming, and complex analytics.

Runs Everywhere
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
'Data > SPARK' 카테고리의 다른 글
| 6. 스파크의 핵심 RDD Resilient Distributed Datasets (1) | 2016.02.12 |
|---|---|
| 5. 웹 기반 명령어 해석기 Zeppelin Install (4) | 2016.02.12 |
| 4. CentOS 스파크 설치 Spark Install "Hello Spark" (5) | 2016.02.05 |
| [Spark] Command (Terminal, Spark, Hadoop) (0) | 2016.01.29 |
| [Spark] URLs (0) | 2016.01.29 |

