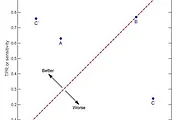
강화 학습 Reinforcement Learning
환경을 탐색하는 에이전트가 현재의 상태를 인식하여 어떤 행동을 취함
에이전트는 환경으로 부터 포상을 얻음
포상은 양수와 음수 둘 다 가능
에이전트가 앞으로 누적될 포상을 최대화 하는 정책을 찾는 방법
강화 학습과 지도학습의 차이점
- 지도 학습 : 이미 알고 있는 지식을 이용해 원하지 않는 행동을 명시적으로 수정하며 모델을 업데이트 해감
- 강화 학습 : 이미 알고 있는 지식과 아직 조사되지 않는 영역을 탐험하는 것 사이의 균형을 잡는 것
즉, 환경이 지속적으로 변해가는 상황에서 트렌드를 실시간으로 분석하고 이를 즉각 반영할 수 있는 온라인 수행
조사되지 않은 영역과의 Trade-off를 조절하는 Multi-armed bandit 문제를 알아본다
Multi-armed Bandit
- 우리는 세상에 대해 잘 모른다
- 세상은 계속 변한다
기계 학습에서의 지도 학습 또한 잘 모르는 세상에 대해 기존의 지식을 통해 알려주고
일반화를 통해 최적화된 모델을 만드는 것이지만,
일반화 된 모델은 2번 째 가정에 의해 지속적으로 업데이트 해야 하는 경우가 생긴다.
- 탐험하기exploartion : 최적안을 두고도 다른 안을 계속 실험 하는 것
- 뽑아먹기exploitation : 최적안이 나왔으면 되도록 최적안으로 사용자를 몰아줘야 이익을 극대화할 수 있음
과학에서의 통제 실험은 언제 어디서나 재현할 수 있음을 가정하지만
비즈니스 환경에서는 오히려 추세가 변하며 이를 빠르게 찾아내 반영 하는 것이 더욱 가치있는 목표가 된다.
얼마의 시간동안 탐험하기 또는 뽑아먹기를 해야 최적이라 간주할 수 있는지 그리고
얼마의 비중으로 뽑아먹기와 탐험하기의 비율을 바꿔갈 것인지 판단해야 하는 것이 어려운 과제이다.
이러한 딜레마와 같은 대표적인 예가 Multi-armed bandit 문제이다.

팔(arm)이 여러 개 있는 슬롯머신이 있다.
각 팔마다 보상 확률이 다르고 플레이어는 어떤 팔의 수익성이 높은지 알지 못한다.
이 상황에서 플레이어가 어떤 순서로 어떤 팔을 얼마나 당겨야 돈을 많이 딸 수 있는지 찾아내는 것이 MAB문제이다.
Multi-armed Bandit 알고리즘
- 환경 상태 집합,
 ;
; - 행동 집합,
 ;
; - 포상(
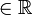 )의 집합;.
)의 집합;.
매 시점  에 에이전트는 자신의 상태(state)
에 에이전트는 자신의 상태(state) 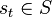 와 가능한 행동(action)
와 가능한 행동(action)  를 가지고 있다.
를 가지고 있다.
에이전트는 어떤 행동 a ∈ A(st) 을 취하고, 환경으로부터 새로운 상태 st+1와 포상(reward) rt+1을 받는다.
종료 상태(terminal state)가 존재하는 경우 누적된 포상값 R을 최대화하며, 종료 상태에 가까워질 수록 탐험을 적게하고 뽑아먹기에 치중해야 한다.

종료 상태가 없는 경우 계속해서 진행되는 미래의 포상이 현재에 얼마나 가치 있는지 할인율γ을 곱해서 누적한다

Multi-armed Bandit 알고리즘 진화
- epsilon-Greedy : 사용자 중 일부는 현재까지 알려진 최적안으로 보내서 뽑아먹기를 하고, 나머지 일부에 대해서는 다시 분기를 하여 전통적인 A/B Testing을 수행하여 새로운 최적안이 나왔는지 알아보는 방식으로 개선한 알고리즘. 단점이 많다.
- Softmax : 지금까지 알려진 성과를 기반으로 성과가 좋은 쪽에 사용자를 좀 더 몰아주는 알고리즘
- Softmax + Temperature : 성과가 좋은 쪽에 사용자를 얼마나 더 몰아줄 것인지("온도")를 조절할 수 있게 하는 방식
- Softmax + Temperature + Annealing : 시간이 지남에 따라 점진적으로 "온도"를 낮춰서 탐험 비율을 낮추는 방식
- UCB1 : 지금까지 알려진 성과 뿐 아니라, 그 성과가 얼마나 많은 실험을 통해 알려진 결과인지(즉 얼마나 확실한지)도 함께 따져서, 덜 확실한 쪽에 더 많은 탐험을 하는 방식
출처 :
https://ko.wikipedia.org/wiki/%EB%A8%B8%EC%8B%A0_%EB%9F%AC%EB%8B%9D
반응형
'Data > Info.' 카테고리의 다른 글
| 빅데이터 비즈니스 모델 (0) | 2018.06.21 |
|---|---|
| 머신러닝 딥러닝 온라인 강의 / SNS / 논문 (0) | 2017.03.23 |
| 기계학습Machine Learnig - 비지도 학습 (0) | 2016.02.07 |
| 기계학습Machine Learning - 지도 학습 유형 (3) | 2016.02.06 |
| 기계학습Machine Learning - 정의, 목적별 분류 (0) | 2016.02.06 |